Basic Curved trajectory analysis#
The objective of this notebook is to learn how to perform linear (curve) trajectory inference from single cell data, starting from a count matrix. Features that significantly changes along the tree will then be extracted and clustered.
Preparing the environment for the tutorial#
The following needs to be run in the command-line
conda create -n scFates -c conda-forge -c r python=3.11 r-mgcv rpy2 -y
conda activate scFates
conda install ipykernel
python -m ipykernel install --user --name scFates --display-name "scFates"
pip install scFates
Importing modules and basic settings#
[1]:
import warnings
warnings.simplefilter(action='ignore', category=Warning)
import os, sys
# to avoid any possible jupyter crashes due to rpy2 not finding the R install on conda
os.environ['R_HOME'] = sys.exec_prefix+"/lib/R/"
import scanpy as sc
import scFates as scf
adata = sc.read('data/hgForebrainGlut.h5ad')
adata.var_names_make_unique()
sc.set_figure_params()
[2]:
sc.settings.verbosity = 3
sc.settings.logfile = sys.stdout
Pre-processing#
[3]:
sc.pp.filter_genes(adata,min_cells=3)
sc.pp.normalize_total(adata)
sc.pp.log1p(adata,base=10)
sc.pp.highly_variable_genes(adata)
filtered out 18081 genes that are detected in less than 3 cells
normalizing counts per cell
finished (0:00:00)
extracting highly variable genes
finished (0:00:00)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
[4]:
adata.raw=adata
[5]:
adata=adata[:,adata.var.highly_variable]
sc.pp.scale(adata)
sc.pp.pca(adata)
computing PCA
with n_comps=50
finished (0:00:00)
[6]:
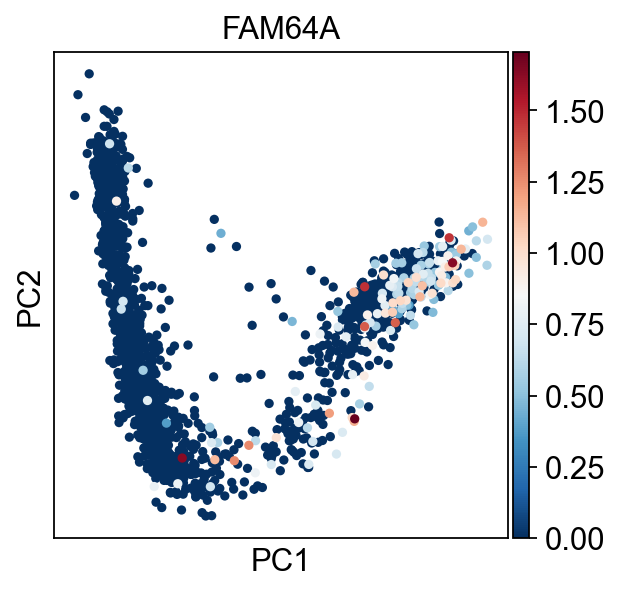
sc.pl.pca(adata,color="FAM64A",cmap="RdBu_r")
Learn curve using ElPiGraph algorithm#
We will infer a principal curve on the 2 first PC components. Any dimensionality reduction in .obsm can be selected using use_rep parameter, and the number of dimension to retain can be set using ndims_rep.
[7]:
scf.tl.curve(adata,Nodes=30,use_rep="X_pca",ndims_rep=2,)
inferring a principal curve --> parameters used
30 principal points, mu = 0.1, lambda = 0.01
finished (0:00:00) --> added
.uns['epg'] dictionnary containing inferred elastic curve generated from elpigraph.
.obsm['X_R'] soft assignment of cells to principal points.
.uns['graph']['B'] adjacency matrix of the principal points.
.uns['graph']['F'], coordinates of principal points in representation space.
Plotting the tree#
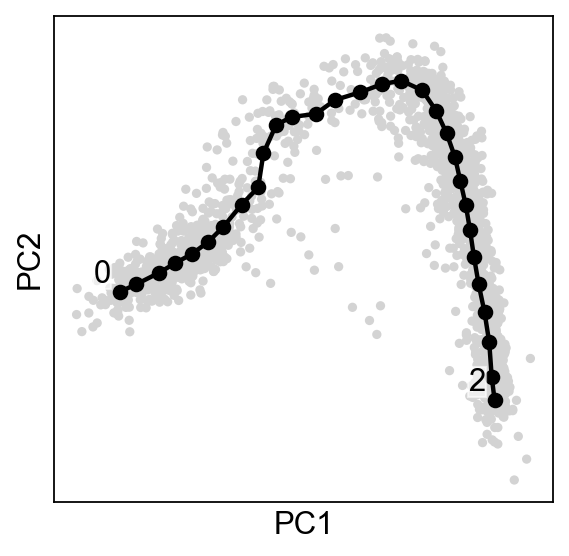
By default the plot function will annotate automatically the tips and the forks ids.
[8]:
scf.pl.graph(adata,basis="pca")
Showing soft assignment of cells#
Now looking at node ID 2 cell assignments, we have continuous values:
[9]:
sc.pl.pca(sc.AnnData(adata.obsm["X_R"],obsm=adata.obsm),color="1",cmap="Reds")

Our cells are assigned to a node by a value between 0 and 1, which allow us to use probabilistic mappings to account for variability.
Selecting a root and computing pseudotime#
Using FAM64A marker, we can confidently tell that the tip 1 is the root.
[10]:
scf.tl.root(adata,"FAM64A")
automatic root selection using FAM64A values
node 0 selected as a root --> added
.uns['graph']['root'] selected root.
.uns['graph']['pp_info'] for each PP, its distance vs root and segment assignment.
.uns['graph']['pp_seg'] segments network information.
Here we are running 100 mappings to account for uncertainty, the pseudotime saved in obs will be the mean of all computed pseudotimes:
[11]:
scf.tl.pseudotime(adata,n_jobs=8,n_map=100,seed=42)
projecting cells onto the principal graph
mappings: 100%|█████████████████████████████████████████████████████████████████████████████████████| 100/100 [00:11<00:00, 8.92it/s]
finished (0:00:11) --> added
.obs['edge'] assigned edge.
.obs['t'] pseudotime value.
.obs['seg'] segment of the tree assigned.
.obs['milestones'] milestone assigned.
.uns['pseudotime_list'] list of cell projection from all mappings.
[12]:
sc.pl.pca(adata,color="t")
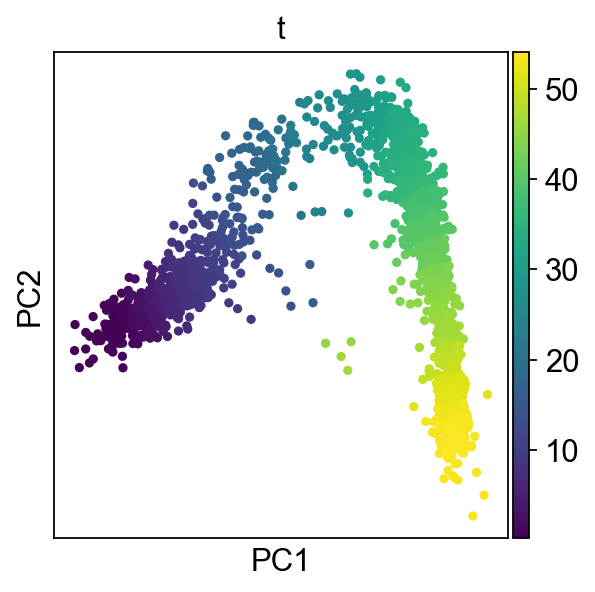
[13]:
scf.pl.trajectory(adata,basis="pca",arrows=True,arrow_offset=3)
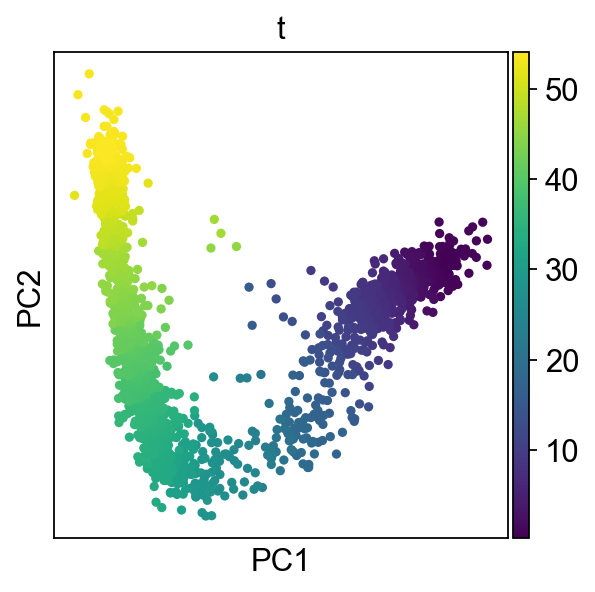
[14]:
adata=adata.raw.to_adata()
Assign and plot milestones#
It is easier to keep track of the miletones by naming them with biological concepts (cell-type, state, …):
[15]:
sc.pl.pca(adata,color="milestones")
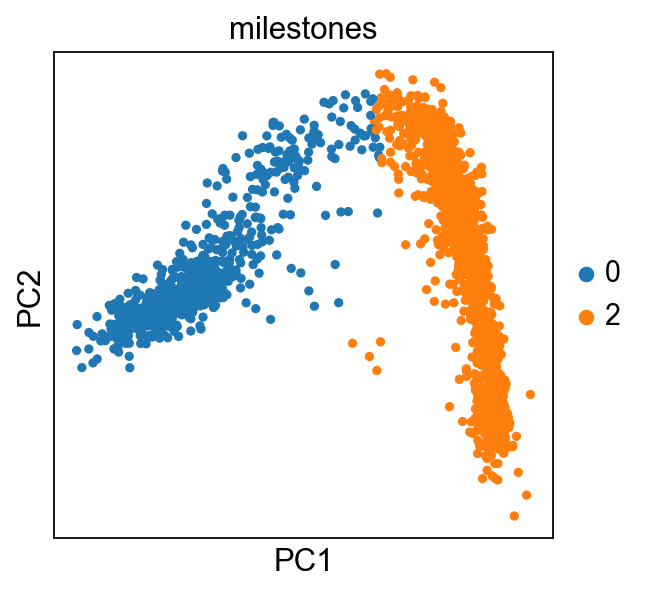
[16]:
start = adata.uns['graph']['root']
end = adata.uns['graph']['tips'][adata.uns['graph']['tips']!=start][0]
scf.tl.rename_milestones(adata,new={str(start):"Radial Glia",str(end): "Neurons"})
[17]:
sc.pl.pca(adata,color="milestones")

[19]:
scf.pl.milestones(adata,basis="pca",annotate=True)
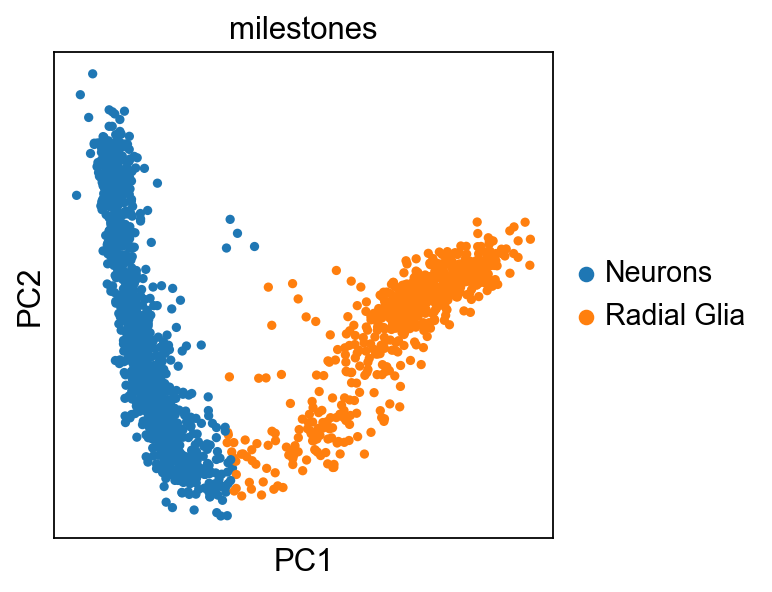
Linearity deviation assessment#
In order to verify that the trajectory we are seeing is not the result of a lienar mixture of two population (caused by doublets), we perform the following test:
[20]:
scf.tl.linearity_deviation(adata,
start_milestone="Radial Glia",
end_milestone="Neurons",
n_jobs=20,plot=True,basis="pca")
Estimation of deviation from linearity
cells on the bridge: 100%|█████████████████████████████████████████████████████████████████████████| 991/991 [00:07<00:00, 140.95it/s]

finished (0:00:07) --> added
.var['Radial Glia->Neurons_rss'], pearson residuals of the linear fit.
.obs['Radial Glia->Neurons_lindev_sel'], cell selections used for the test.
[21]:
scf.pl.linearity_deviation(adata,
start_milestone="Radial Glia",
end_milestone="Neurons")
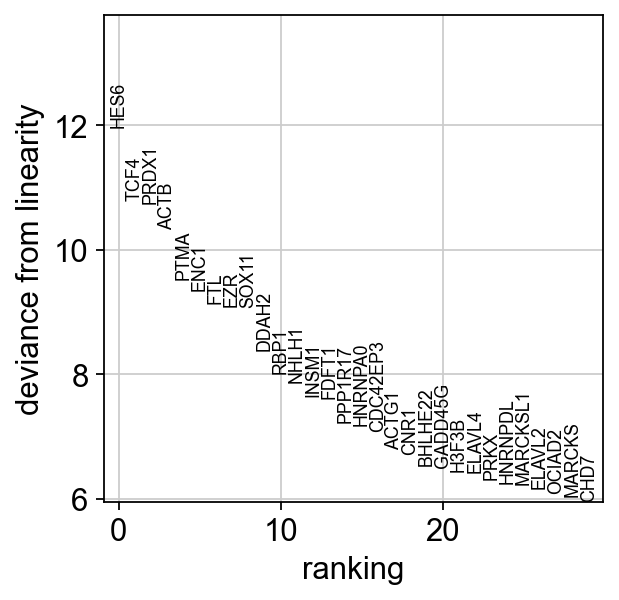
We have markers that highly deviate from linearity, most of which are biologically relevant. We can confidently say that this is a developmental bridge.
[23]:
sc.pl.pca(adata,color=["HES6","TCF4","PRDX1"],cmap="RdBu_r")
Significantly changing feature along pseudotime test#
[24]:
scf.tl.test_association(adata,n_jobs=20)
test features for association with the trajectory
single mapping : 100%|██████████| 14657/14657 [03:39<00:00, 66.90it/s]
found 147 significant features (0:03:39) --> added
.var['p_val'] values from statistical test.
.var['fdr'] corrected values from multiple testing.
.var['st'] proportion of mapping in which feature is significant.
.var['A'] amplitue of change of tested feature.
.var['signi'] feature is significantly changing along pseudotime.
.uns['stat_assoc_list'] list of fitted features on the graph for all mappings.
We can change the amplitude parameter to get more significant genes, this can be done without redoing all the tests (reapply_filters parameter)
[25]:
scf.tl.test_association(adata,reapply_filters=True,A_cut=.5)
scf.pl.test_association(adata)
reapplied filters, 635 significant features

Fitting & clustering significant features#
Warning
anndata format can currently only keep the same dimensions for each of its layers. This means that adding the layer for fitted features will lead to dataset subsetted to only those!
By default the function fit will keep the whole dataset under adata.raw (parameter save_raw)
[26]:
scf.tl.fit(adata,n_jobs=20)
fit features associated with the trajectory
single mapping : 100%|██████████| 635/635 [00:17<00:00, 35.64it/s]
finished (adata subsetted to keep only fitted features!) (0:00:18) --> added
.layers['fitted'], fitted features on the trajectory for all mappings.
.raw, unfiltered data.
[27]:
scf.pl.single_trend(adata,"HES6",basis="pca",color_exp="k")
scf.pl.single_trend(adata,"TCF4",basis="pca",color_exp="k")
scf.pl.single_trend(adata,"PRDX1",basis="pca",color_exp="k")



[28]:
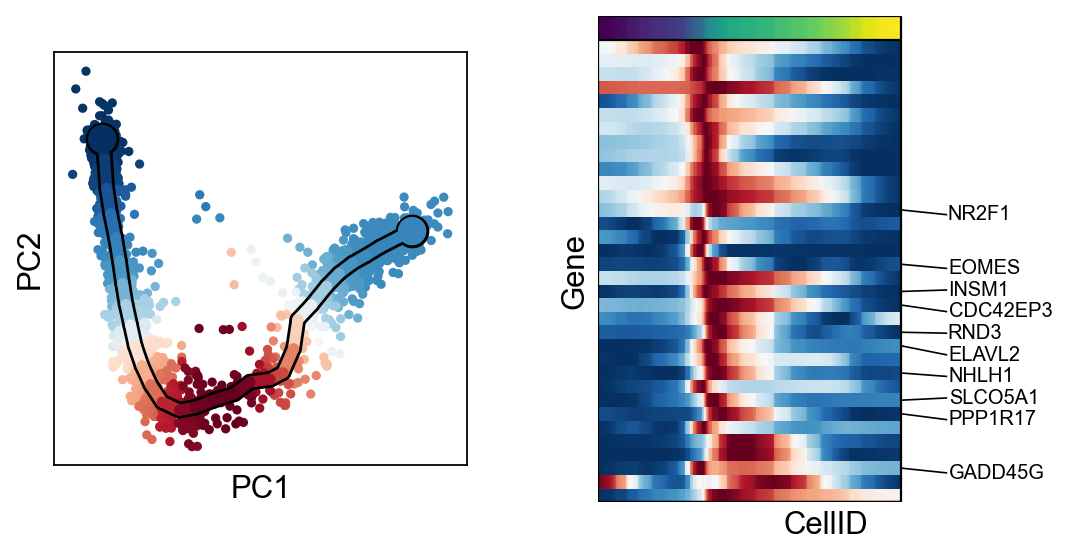
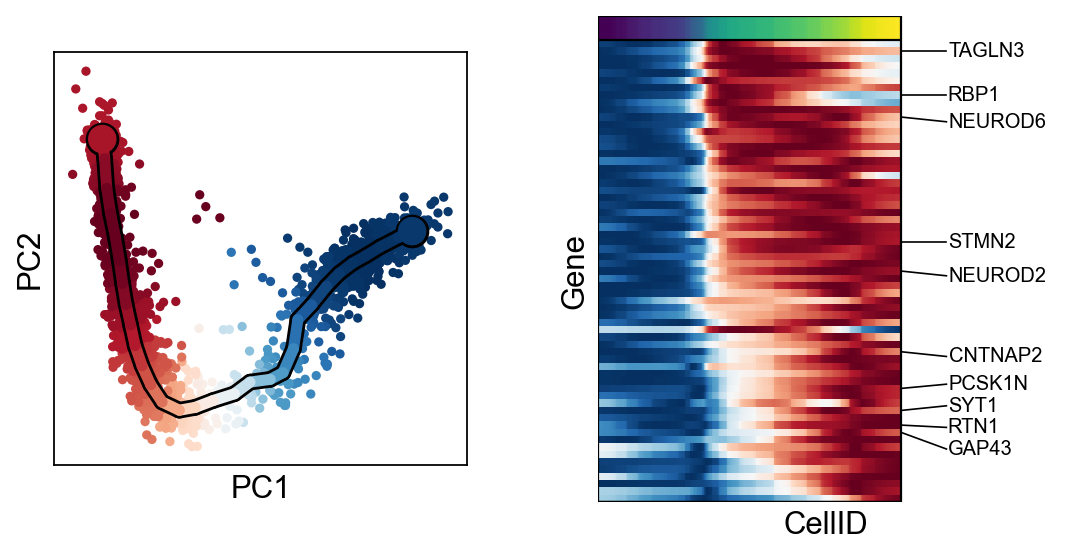
scf.tl.cluster(adata,n_neighbors=100,metric="correlation")
Clustering features using fitted layer
computing PCA
with n_comps=50
finished (0:00:01)
computing neighbors
using 'X_pca' with n_pcs = 50
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:11)
running Leiden clustering
finished: found 6 clusters and added
'leiden', the cluster labels (adata.obs, categorical) (0:00:01)
finished (0:00:13) --> added
.var['clusters'] identified modules.
[29]:
adata.var.clusters.unique()
[29]:
['3', '1', '0', '5', '2', '4']
Categories (6, object): ['0', '1', '2', '3', '4', '5']
[30]:
for c in adata.var["clusters"].unique():
scf.pl.trends(adata,features=adata.var_names[adata.var.clusters==c],basis="pca")